AI语音识别 && 自搭建语义相似度服务生产实践
1. 需求背景
用户做英语单词记忆训练时,看着屏幕上的英语单词,点击录音按钮,念出单词的英语发音和中文意思,马上给出英语发音评分(具体到每个音素的评分)和中文翻译评分。
整个需求的难点在于:
- 整个过程中用户给到的音频是一英一中的连续发音,需要区分出英文发音的部分和中文释义的发音的部分,才能进行评分;
- 逻辑上能保证服务能区分出英文发音和中文释义发音后,还需要保证评分结果的快速响应;
2. 技术方案
1. 流程拆解
- 客户端在麦克风接收到音频流后;
- 并行调用发音评估服务(获取英文发音评分)和语音识别服务(获取中文释义文本识别结果);
- 获取到中文释义的文本识别结果后,再与原本的释义做语义相似度对比,得到中文翻译准确度的评分。
2. 分析调研
2.1 发音评估
发音评估部分,决定使用微软的发音评估服务。对于需求场景中的一英一中音频,指定语言为en-US,并使用脚本化评估的方式,将英文单词文本设置到ReferenceText参数中,就能准确对英语发音的部分给出准确性、流畅性、完整性、发音韵律四项评分。音频后面的中文发音部分不在ReferenceText中,一般会识别为插入内容,在评分返回值对象中的属性ErrorType: Insertion标识,并不影响英文发音评分的结果。
下面是微软发音评估使用示例: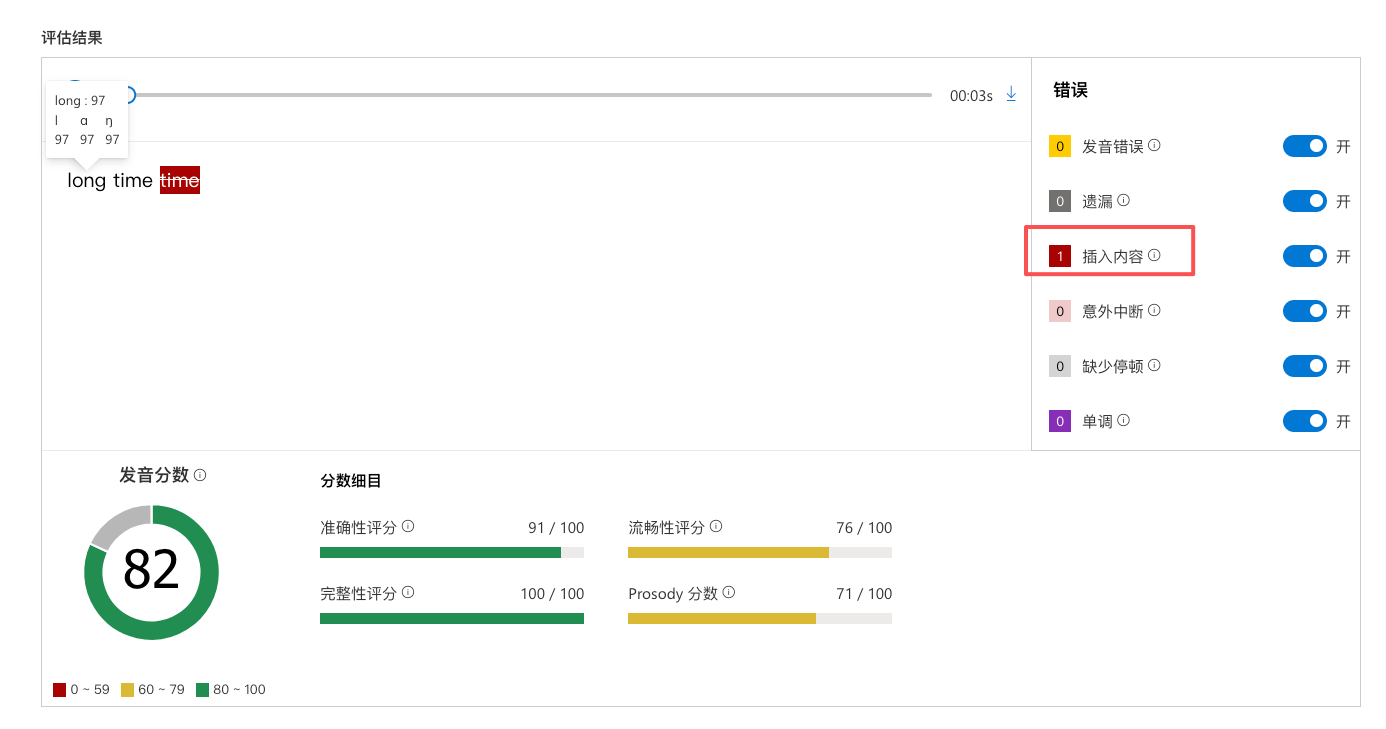
发音评估的定价为3 + 3.05 = ¥6.05/小时,按秒来增量计费。
官方相关文档:
微软Azure获取发音评估结果–服务接口文档
微软 Speech Studio 上体验发音评估
微软Azure发音评估国内定价
微软Azure发音评估海外定价
2.2 语音识别
中文释义的发音部分,决定使用火山的大模型流式语音识别API中的豆包流式语音识别模型2.0来保证准确识别,我们采用了bigmodel_nostream流式输入模式接口,默认支持中英文识别,同时支持配置热词直传(也即在请求参数中携带本次识别需要的热词,以提高识别的准确度)。
在调研初期,发现语音识别有两种识别异常的情况:
- 用户的英文发音不标准,或者是单词音节太短,导致英文单词的发音识别为中文,比如,单词
rule,用户训练时发音rule 尺子,其他的 asr 服务(例如微软语音识别、ios 自带的 asr)可能识别为撸了尺子。 - 中文的同音字词,导致识别偏差,例如单词
poster,用户训练时发音poster 海报,可能被识别为poster 海豹。使用火山的流式语音识别,设置热词直传参数,将单词的中英文作为热词传递,就能大大提高识别的准确度。
豆包流式语音识别模型2.0的定价为 ¥ 1/小时
官方相关文档:
火山引擎-豆包语音-大模型流式语音识别API
火山引擎-豆包语音-定价
2.3 中文翻译评判
中文翻译的评分部分,实现上,就是通过判断单词实际中文释义与用户发音识别结果的中文部分做语义相似度的比对,将比对的结果的置信度分数,分为优秀、良好、较差,三级评分。
语义相似度服务接口的具体实现上,分别调研了 hanlp 和 spacy 这两个 python的 nlp 库,并使用了各自官方提供的预训练模型,具体效果如下:
1 | # hanlp使用示例 |
1 | # spacy使用示例 |
后续用更多数据做测试,发现 hanlp 对中文词汇的语义相似度对比更为准确,在某些名词对比可能误差较大,但是总体符合需求要求。后面应用到灰度环境,小范围用户验证,效果也比较好。
生产环境示例使用,日志示例:
3. 交互时序图
sequenceDiagram
actor user as 用户
participant front as 客户端
participant microsoft as 微软发音评估
participant volcano as 豆包语音识别
participant backend as 后端服务
note over user,backend: 核心流程:发音评估 + 语音识别 + 语义对比
user ->> +front: 输入一英一中语音
par 并行处理 1:发音评估
front ->> +microsoft: 发送音频流请求发音评估
note right of microsoft: 评估维度:准确度/流利度/<br>完整度/发音韵律
microsoft -->> -front: 返回评估结果
and 并行处理 2:语音识别
front ->> +volcano: 发送音频流(配置热词直传)
volcano -->> -front: 返回音频的文本识别结果
end
deactivate front
front ->> +backend: 提交识别结果 + 原本的中文释义
activate front
note left of backend: 第三方库<br>语义相似度算法比对
backend-->>-front: 返回相似度分数+等级
deactivate front
front-->>user: 展示英文发音评分<br>&& 中文翻译准确度分值